Preprocess for Display
Once the layouts have been identified, the subsequent step involves ranking the images and cropping them to fit the designated rectangles.
Essentially, this process entails determining which objects should be featured in larger rectangles and devising a strategy for cropping the images to ensure they fit appropriately within these spaces.
Measuring Image Quality for Optimal Display
To enhance the display process, we intend to incorporate a metric that reflects the quality of each image. While image quality can be subjective, our primary goal is clear: to make the final poster as visually appealing as possible.
With a variety of candidate images for each group and rectangles of differing sizes, the objective is to place higher quality images in the larger rectangles, thereby optimizing the overall aesthetic.
Given the vast array of open-source image quality assessment tools available, we’ve chosen to utilize the comprehensive PyTorch Image Quality (PIQ) package. This tool allows us to quantitatively evaluate the quality of an image, providing a reliable measure to guide our image selection and placement process.
![]()
Image source: PyTorch Image Quality (PIQ)
PyTorch Image Quality (PIQ) is a collection of measures and metrics for image quality assessment. PIQ helps you to concentrate on your experiments without the boilerplate code. The library contains a set of measures and metrics that is continually getting extended. For measures/metrics that can be used as loss functions, corresponding PyTorch modules are implemented.
CLIP-IQA for Image Quality Assessment
Among the various metrics available, we’ve chosen to use CLIP-IQA, a CLIP-based image quality assessment. Higher scores indicate better image quality. While the underlying mechanisms of CLIP-IQA are sophisticated, leveraging the PIQ package simplifies the process to a straightforward function call.

Image source: Exploring CLIP for Assessing the Look and Feel of Images
To ensure a comprehensive evaluation, we also incorporate measurements from TV (Total Variation) and BRISQUE (Blind/Referenceless Image Spatial Quality Evaluator). These additional metrics, quicker to compute than CLIP-IQA, serve as baselines against the more time-intensive CLIP-IQA scores. This comparative approach helps us determine if the additional computational time for CLIP-IQA is justified by a significant improvement in quality assessment.
Insights from Image Quality Metrics
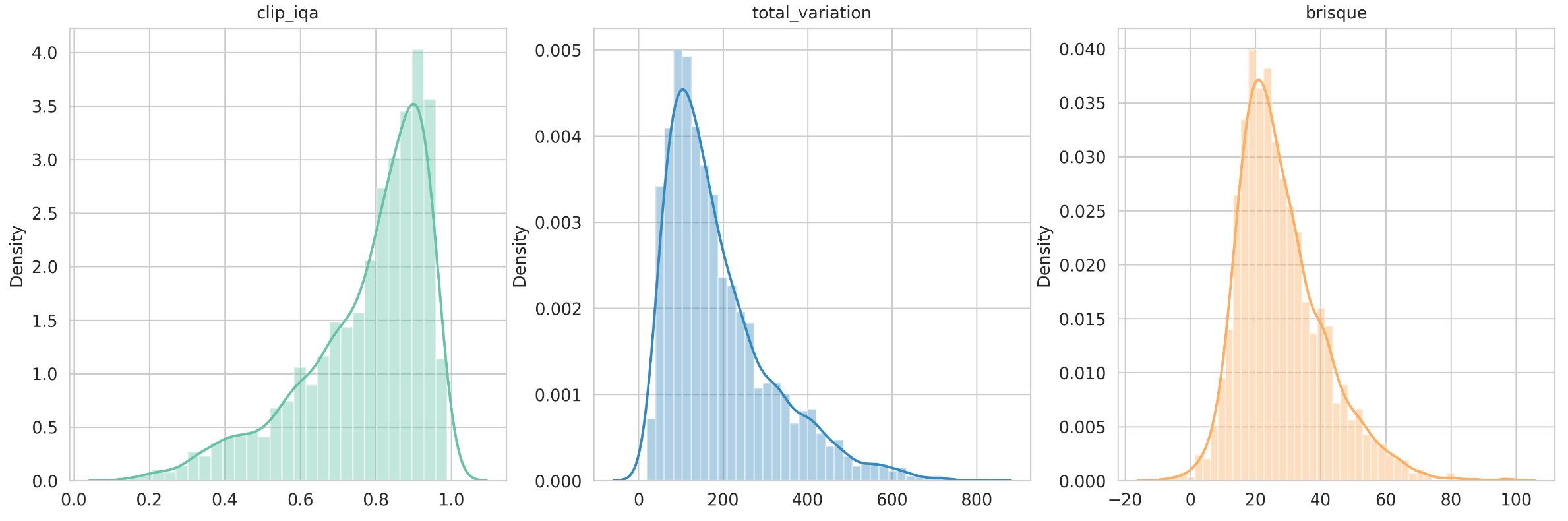
Here, we explore the distributions of Total Variation (TV), Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE), and CLIP-IQA, which illuminate the quality landscape of our image dataset and reaffirm our selection of CLIP-IQA as the optimal metric.
-
Total Variation (TV): This metric quantifies image noise and texture by summing the absolute differences between adjacent pixels. While a lower TV indicates a smoother image, it’s not always synonymous with higher quality due to its inability to distinguish between detailed textures and noise. Our dataset’s distribution suggests a predominance of smoother images, indicating generally low noise levels but not necessarily high quality.
-
Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE): Operating on natural scene statistics, BRISQUE evaluates images without reference images, with lower scores denoting better quality. The distribution in our dataset leans toward lower scores, suggesting a collection of good-quality images. However, like TV, the scale of BRISQUE isn’t fixed, with the upper limit varying based on the image’s distortion level.
-
CLIP-IQA: Standing out with its normalized range (0 to 1) and its alignment with human judgment, CLIP-IQA is our metric of choice. The distribution of CLIP-IQA scores underlines its effectiveness in differentiating between high and low-quality images, making it a reliable tool for assessing image appeal and relevance.
Visualizing Quality with CLIP-IQA
To demonstrate the practical implications of these findings, we showcase the top and bottom images as per their CLIP-IQA scores, providing a visual understanding of what the metric deems as high and low quality.

Top 10 images with highest CLIP-IQA score.
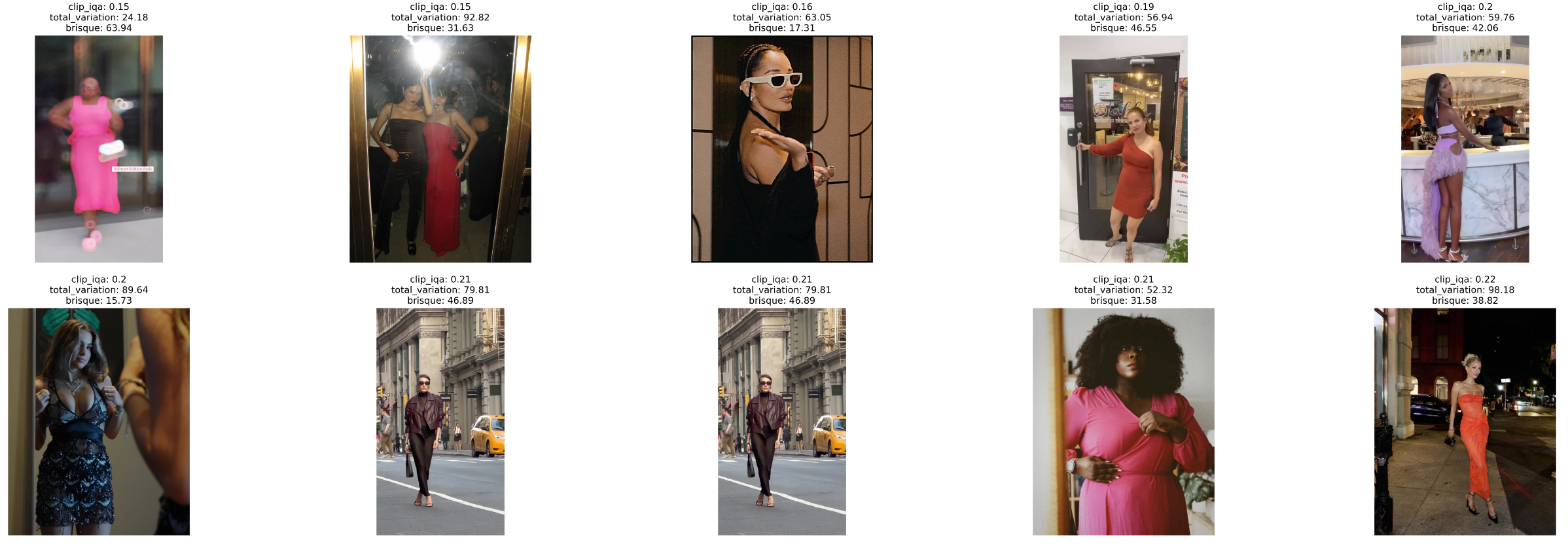
Top 10 images with lowest CLIP-IQA score.
Strategies for Optimized Image Cropping
Effective image cropping is crucial for focusing on the target fashion object while retaining a natural context, especially the human element in the image. The cropping strategy should adapt based on the type of fashion item to ensure the most relevant and appealing part of the image is displayed.
-
For Accessories (e.g., Sunglasses): The goal is to center on the accessory while including enough of the face to maintain a natural look. For sunglasses, this means capturing the entire face to provide context and enhance the accessory’s visual appeal.
-
For Upper Body Wear: The focus should extend to the upper body, including the face. This approach balances the emphasis on the garment with a natural, human-centric presentation. Cropping away the lower body doesn’t detract from the overall effect as the key details are typically above the waist.
-
For Lower Body Wear: A full-body view is preferable. Cropping just the lower half can result in an unnatural and disjointed appearance. Displaying the entire body provides a coherent and complete view, placing the lower wear in its full context.
To implement this nuanced cropping, we need a reference point, ideally the bounding box of the human figure in the image. This reference will guide the crop, ensuring it’s tailored to both the fashion object and its interaction with the human form.
Detecting Human Figure with YOLOV8
To refine the image cropping process, we utilize the YOLOV8 model, renowned for its high accuracy and effective “person” label for detecting human figures.
Once we obtain various person bounding boxes from the image, we choose the one that demonstrates the most substantial overlap with the target fashion object.

Image source: Ultralytics YOLOv8 Object Detection
For instance, in scenarios where multiple person bounding boxes are detected, the one with the most substantial overlap with the target object is chosen as the reference. It’s highlighted in black in the visualization, while the target object is marked in red.


Even in cases where a single individual is present but multiple bounding boxes are detected (often due to the model capturing different parts of the person or their accessories), we select the bounding box with the larger Intersection over Union (IoU) with the target object’s bounding box.

This approach ensures that the most relevant section of the image is emphasized, balancing the focus between the fashion item and its human context.
Summary of Preprocess Steps
Following the steps outlined above, each image in the dataset now comes supplemented with additional information, essential for the forthcoming cropping and display processes.
-
Image Quality Scores: A trio of metrics—CLIP-IQA, Total Variation (TV), and Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE)—are calculated for each image, providing a multifaceted assessment of image quality.
-
The Reference Person Bounding Box: The selected person bounding box to guide the cropping process if any.
Implementation Details
Input
| Name | Description |
|---|---|
ins_posts_clusters.csv | csv file containing selected objects and their clusters |
ins_posts_clusters_selected_group.csv | csv file containing selected clusters and their annotated tags and tag_groups |
Process
| Code | Description |
|---|---|
codes/poster_generation/preprocess_for_display.ipynb | Preprocess the images for poster display |
Output
| Name | Description |
|---|---|
ins_posts_clusters_selected_group_objects_quality_person.csv | csv file containing selected objects and their quality scores and person bounding boxes |
Data Sample:
{
"cluster": "cluster_484",
"tag": "pink",
"tag_group": "pink",
"batch_folder": "ins_posts_3",
"username": "wuzg00d",
"res_name": "773b9dfbf7c2102bb3f10db62efd6e20.json",
"bbox": "[561.7132568359375, 861.585693359375, 788.7639770507812, 1100.5401611328125]",
"simple_tag": "shirt",
"score": 0.46,
"idx": 6,
"group_name": "coat jacket | dress garment | dress shirt",
"image_name": "773b9dfbf7c2102bb3f10db62efd6e20",
"dist": 0.68329793,
"sim": 0.7277999,
"obj_area": 88517.11739822105,
"image_path": "/mnt/ssd3/jiangchun/data/ins_posts_batch/ins_posts_3/wuzg00d/images/773b9dfbf7c2102bb3f10db62efd6e20.jpg",
"brisque": 29.93035888671875,
"total_variation": 350.642822265625,
"clip_iqa": 0.912834644317627,
"yolov8_bboxes": "[{'class_name': 'person', 'bbox': [541.15, 720.5299, 961.698, 1798.5879], 'area': 453375.1, 'iou': 0.1196686468984351}]",
"person_bbox": "{'class_name': 'person', 'bbox': [541.15, 720.5299, 961.698, 1798.5879], 'area': 453375.1, 'iou': 0.11966863580353485}"
}