Cluster Review and Selection
Group and Display by Clusters
The open-source library Fiftyone is utilized for reviewing and selecting clusters of interest, thanks to its powerful dataset visualization capabilities.

Image source: Fiftyone
The “Create dynamic group” feature in Fiftyone is exceptionally useful for cluster analysis, as it permits users to dynamically group samples based on a specific field.
In the context of this project, this feature is leveraged to group samples according to their assigned clusters. This organization enables a systematic and efficient review of each cluster, streamlining the process of evaluating and understanding the characteristics of each group.
Create dynamic group by “cluster”, ordered by “dist”.
A potential enhancement to the “Create dynamic group” feature would be the addition of dynamic group size information. As an interim solution, I have manually added an attribute called “cluster_size” to each sample within the dataset to indicate the number of samples in each cluster. While this method serves its purpose, it lacks adaptability and convenience. As the purpose of “Create dynamic group” is to form groups dynamically, it would be ideal if the group size could be displayed dynamically as well.
After grouping, extra information is displayed to facilitate more informative browsing experience.
Extra sample information.
This additional information includes:
- group_name: Remember that each object tag has been assigned to a tag_group in the object grouping and filtering session. The group_name here is actually the name of the tag_group. This provides an indicative description of what might be contained within the cluster, offering a preliminary understanding of the cluster’s contents.
- cluster_size: Indicates the total number of samples present in the cluster, giving an idea of the cluster’s magnitude.
- sim: Represents the cosine similarity score between each sample and the cluster’s center. This score helps in assessing how closely each sample aligns with the central theme or characteristic of the cluster.
- dist: Shows the euclidean distance between each sample and the cluster center. Similar to the cosine similarity score, this metric also helps in evaluating how closely each sample aligns with the central theme or characteristic of the cluster.
Round One Review: Initial Annotation
After the setup, the next step is to browse through the clusters and select the ones of interest. Since the samples are already organized into clusters, browsing can be efficiently conducted by groups. Furthermore, annotating an entire cluster can be conveniently achieved by adding a sample tag to just a single sample within that cluster.
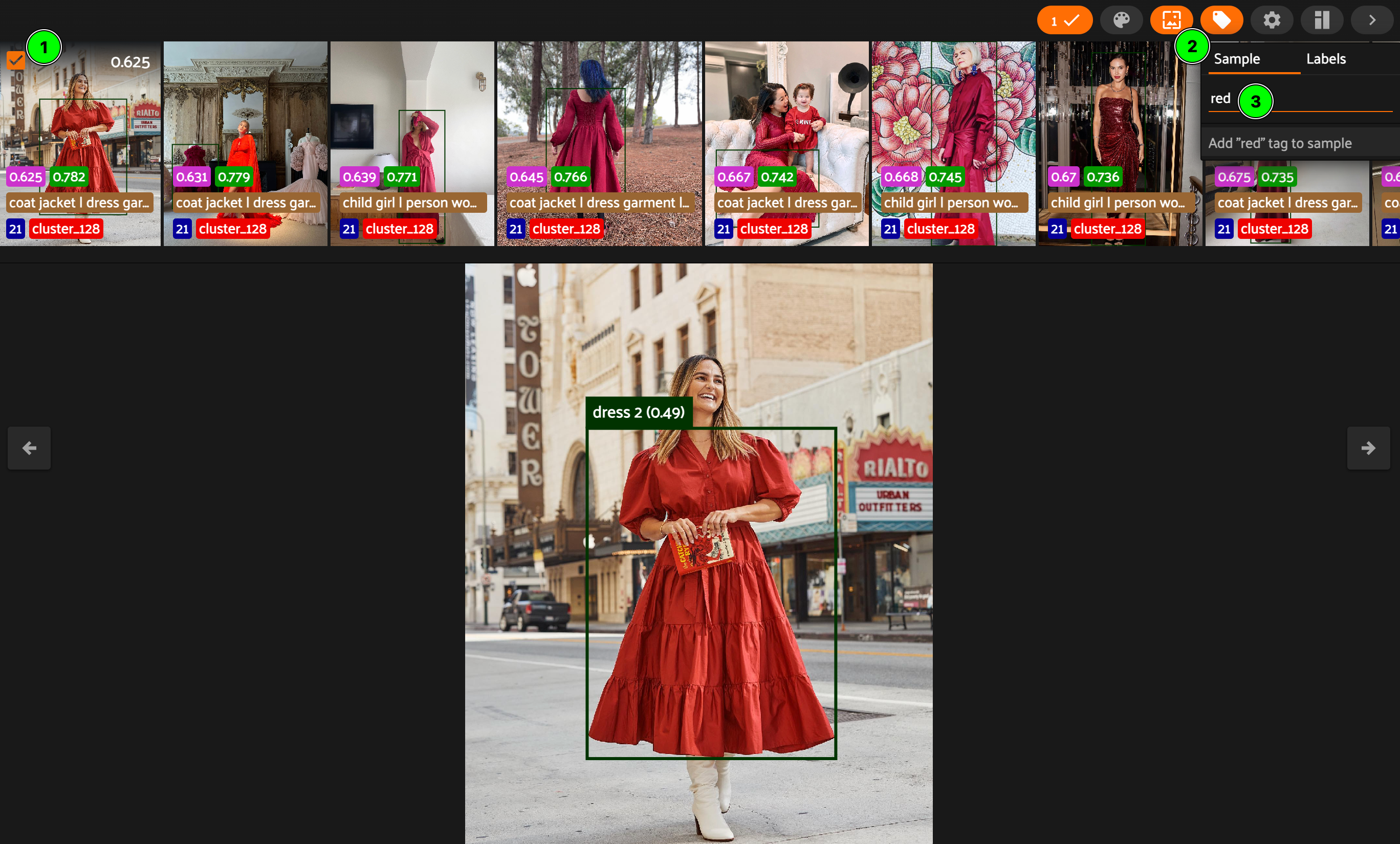 Annotate the cluster as a whole.
Annotate the cluster as a whole.
My strategy is to initially annotate the clusters with simple, straightforward tags, like “black”, “red”, “sunglasses”, etc. Due to the nature of the KMeans clustering algorithm, it’s common to encounter clusters that are quite similar.
Using basic tags for these clusters facilitates the grouping of similar clusters in later stages. This approach not only streamlines the initial review process but also sets a solid foundation for more efficient organization and analysis of the clusters subsequently.
After the initial annotation, here are the top 10 tags along with the highest number of associated clusters:
| Tag | Number of Clusters |
|---|---|
| sunglasses | 12 |
| pink | 8 |
| white_dress | 6 |
| black_boots | 5 |
| yellow | 5 |
| denim | 4 |
| cap | 4 |
| black_sexy | 4 |
| white_suit | 3 |
| black_bag | 3 |
Round Two Review: Refinement
Utilizing the general tags applied in the initial annotation phase, we can efficiently conduct a second round of browsing. This allows us to re-examine clusters that are grouped under similar tags and further refine our analysis.
For instance, we can collectively review clusters tagged with “sunglasses” to discern if there are any particularly unique clusters within this category. Additionally, we can review all clusters associated with the color black, such as “black_boots”, “black_sexy”, “black_bag”, etc., to identify noteworthy clusters featuring black fashion items.
The purpose of this second round of browsing is to pinpoint genuinely interesting items by reassessing clusters that are similar and, where appropriate, merging them.
Results
The final interesting groups identified through this process are outlined below.
 The selected groups.
The selected groups.
In this context, a “group” refers to a collection that may consist of several similar clusters combined into a single category.
| Group | Clusters | Num Samples |
|---|---|---|
| pink | 40, 56, 72, 257, 325, 477, 484, 568 | 385 |
| bossy female | 175, 420, 424 | 239 |
| red | 69, 128, 316, 426 | 235 |
| black | 537 | 208 |
| weave | 195, 195, 244, 342 | 207 |
| futural sunglasses | 107, 530 | 185 |
| orange | 5, 205, 439 | 172 |
| medal_earring | 136, 324 | 115 |
| green | 331, 458, 361, 376 | 102 |
| denim wear | 517 | 77 |
| black and shining | 333, 372 | 73 |
| bright_floral | 196, 367 | 62 |
| stride | 309, 474, 509 | 62 |
| blue | 147, 498 | 60 |
| white | 178 | 59 |
| light_floral | 25, 510, 0 | 53 |
| warm and soft | 53 | 49 |
| leather | 217 | 40 |
| purple | 10 | 38 |
| cool_floral | 518, 209 | 31 |
| colorful | 405 | 29 |
| yellow | 368 | 22 |
Implementation Details
Input
| Name | Description |
|---|---|
ins_posts_clusters.csv | csv file containing selected objects and their clusters |
Process
| Code | Description |
|---|---|
codes/cluster_analysis/clustering.ipynb | Clustering on selected objects and pick the clusters of interest |
Output
| Name | Description |
|---|---|
ins_posts_clusters_selected_group.csv | csv file containing selected clusters and their annotated tags and tag_groups |
Data Sample:
{
"img_path": "/mnt/ssd3/jiangchun/data/ins_posts_batch/ins_posts_2/OliviaLazuardy/images/95fee94fead30f5caca05a6ab1eafc3e.jpg",
"image_name": "95fee94fead30f5caca05a6ab1eafc3e",
"cluster": "cluster_537",
"tag": "black_dress | classic",
"tag_group": "black"
}