Data Crawling: Crawl Instagram Posts
The data collection process employs the open-source Instagram Crawler, which has been slightly modified for this specific use case.
For each account, both profile information and the latest 100 posts are collected. The cut-off time for these posts is subject to when the data from each influencer is gathered, with an approximate date around September 18, 2023.
Currently, the method of collecting only the most recent 100 posts is chosen for simplicity. However, this approach has a limitation as the posts may not fall within the same time frame, with some being quite outdated.
A more effective strategy could be to crawl posts from a specific time period, such as the past three months. Additionally, setting a cap on the number of posts per influencer, perhaps at 100, would help maintain dataset balance. This prevents any single influencer from overly dominating the dataset with an excessive number of posts.
The Crawled Data
Consider the account of camilacoelho:
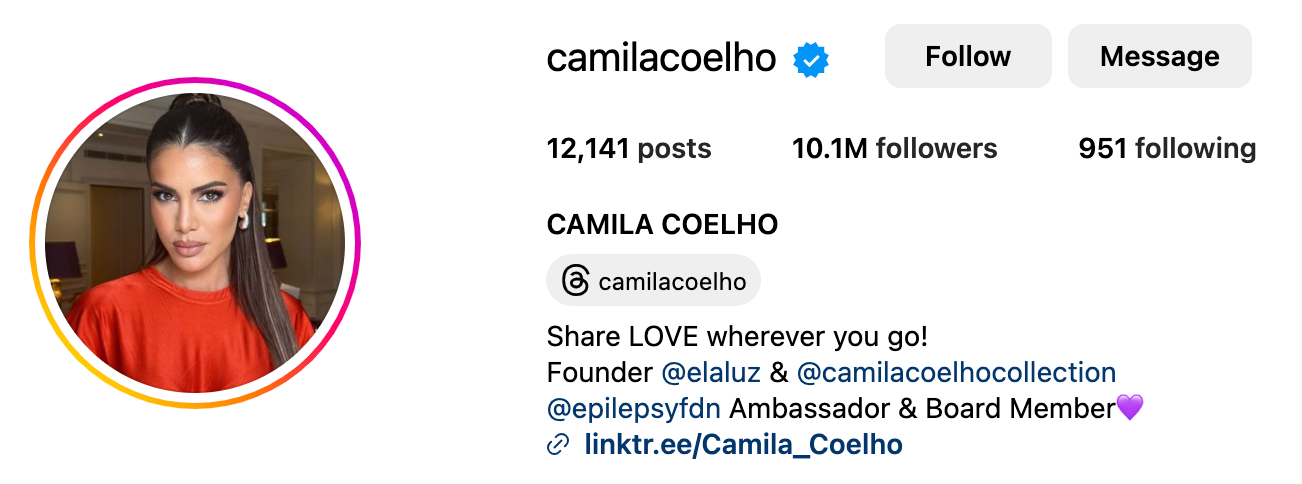
Image source: camilacoelho
The profile information contains:
{
"name": "camilacoelho",
"desc": "CAMILA COELHO\nShare LOVE wherever you go!\nFounder & Creative Director of @elaluz & @camilacoelhocollection\n@epilepsyfdn Ambassador & Board Member💜\nlinktr.ee/Camila_Coelho",
"photo_url": "https://scontent-xsp1-1.cdninstagram.com/v/t51.2885-19/402327079_3692889090991256_4723081888164946863_n.jpg?stp=dst-jpg_s320x320&_nc_ht=scontent-xsp1-1.cdninstagram.com&_nc_cat=1&_nc_ohc=gEHxOCBUWHgAX9WtOVy&edm=AOQ1c0wBAAAA&ccb=7-5&oh=00_AfCR9v982n9WS4yzbj4RW8ZriohKyTtY-qrmFInygohMPA&oe=6577AF70&_nc_sid=8b3546",
"post_num": 12141,
"follower_num": "10.1M",
"following_num": "951"
}
Each post’s metadata and cover image are gathered. For simplicity, if a post contains multiple images, only the first image is collected, under the assumption that it should be the most representative and significant, as it is selected as the cover by the author. The cover image is downloaded, and its MD5 hash is calculated to serve as the file name when saving the image locally.
For example, the collected data for a specific post is organized in the table below:
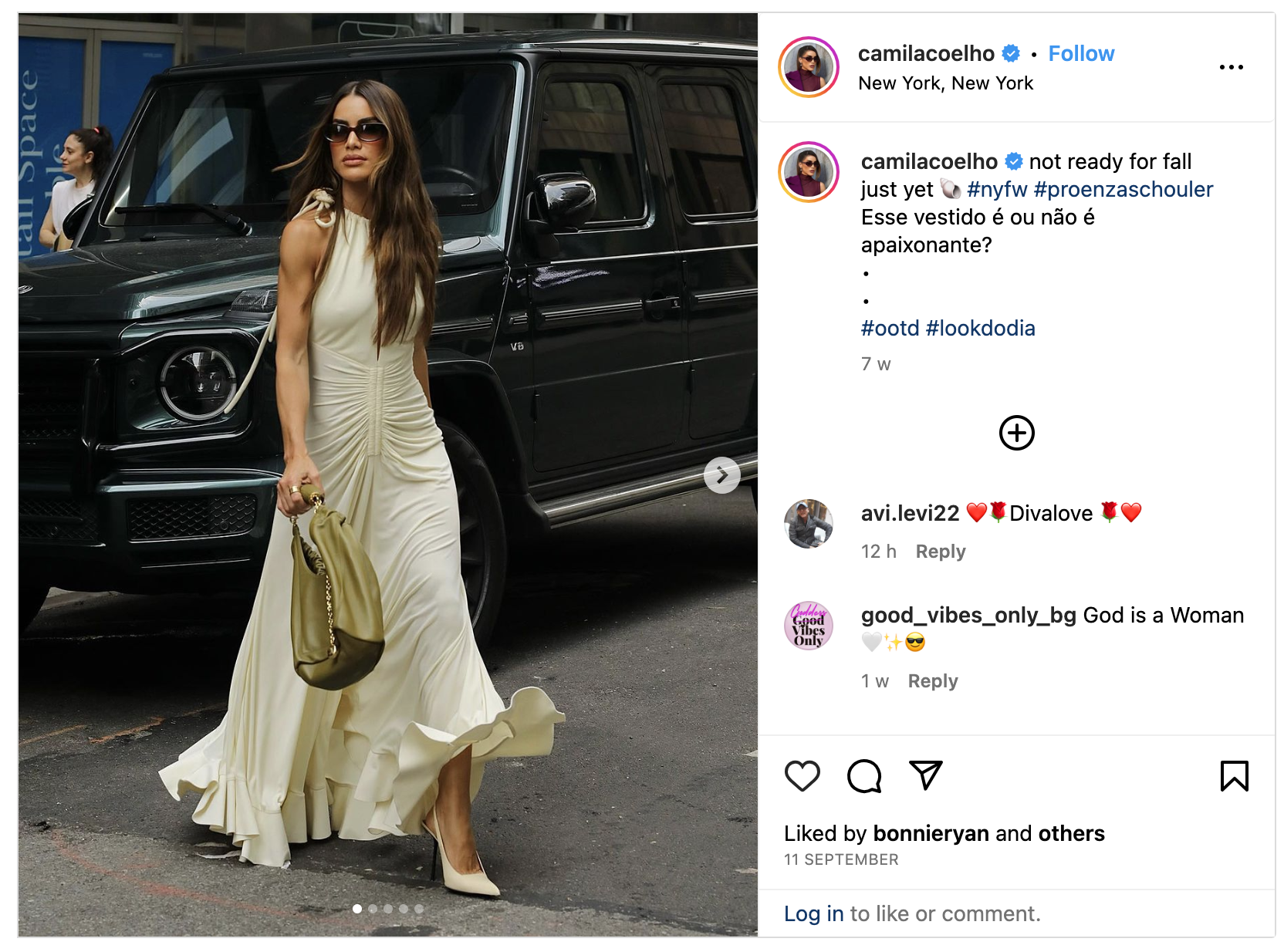
Image source: post by camilacoelho
| Meta Key | Description | Example |
|---|---|---|
| key | The URL of the post | https://www.instagram.com/p/CxBKtEPgLMd/ |
| caption | The caption of the post | Photo shared by CAMILA COELHO on September 10, 2023 tagging @proenzaschouler, @loewe, @ysl, and @dezi. |
| img_url | The URL of the cover image | https://instagram.fsin3-1.fna.fbcdn.net/v/t39.30808-6/375828381_18396938023047347_1280470285330268014_n.jpg?… |
| datetime | The time when the post was created, useful for time-based analysis | 2023-09-10T16:36:33.000Z |
| image_name | The MD5 hash of the cover image, used as the file name for local storage | 5f14923784fb039316b83747afb59e15 |
It’s important to mention that the img_url has a limited validity period and will eventually expire. Therefore, it is essential to download the cover image concurrently with the crawling process and store it locally for future use.
Data Statistics
The final dataset consists of 647 accounts and a total of 30,337 posts. Employing the approach of gathering the most recent 100 posts per account, about 80% of these posts date back to the year 2023. The median post count for each account stands at 46.
Given the manual nature of the data collection process, the dataset is relatively small. However, it is sufficient for the purpose of this project, which is to demonstrate the feasibility of analyzing fashion trends on Instagram using deep learning technology.
Implementation Details
Input
| Name | Description |
|---|---|
fashion_influencers.json | A JSON file containing a list of fashion influencers’ Instagram accounts |
Data Sample:
{
"accounts": [
"@zoesugg",
"@princeandthebaker"
]
}
Process
| Code | Description |
|---|---|
codes/crawler/crawler.py | A Python script for crawling Instagram posts |
Output
| Name | Description |
|---|---|
ins_posts | A folder containing the crawled Instagram posts, organized by account subfolders |
Folder Structure:
ins_posts
├── 3milythestrange
│ ├── 3milythestrange_posts.json
│ ├── 3milythestrange_profile.json
│ └── images
│ ├── 017f490854ef43e87b4f8b7f7bc179ab.jpg
│ ├── ...
│ └── f99bfbca20158474c6d18cb2fe96253a.jpg
└── zoesugg
├── images
│ ├── 0d959b92caab0191b7e1308912060c7b.jpg
│ ├── ...
│ └── f0cec394b87539e62889eb50f264966d.jpg
├── zoesugg_posts.json
└── zoesugg_profile.json
Due to the large size of the ins_posts folder, it has been divided into batches for separate uploads to the server.
Consequently, in later parts of the process, the file path will be structured as <data_dir>/ins_posts_batch/ins_posts_<idx>/<username>. The overall folder structure remains consistent, with the addition of an extra level indicating the batch index, denoted as ins_posts_<idx>.