Zero-shot Text Classification
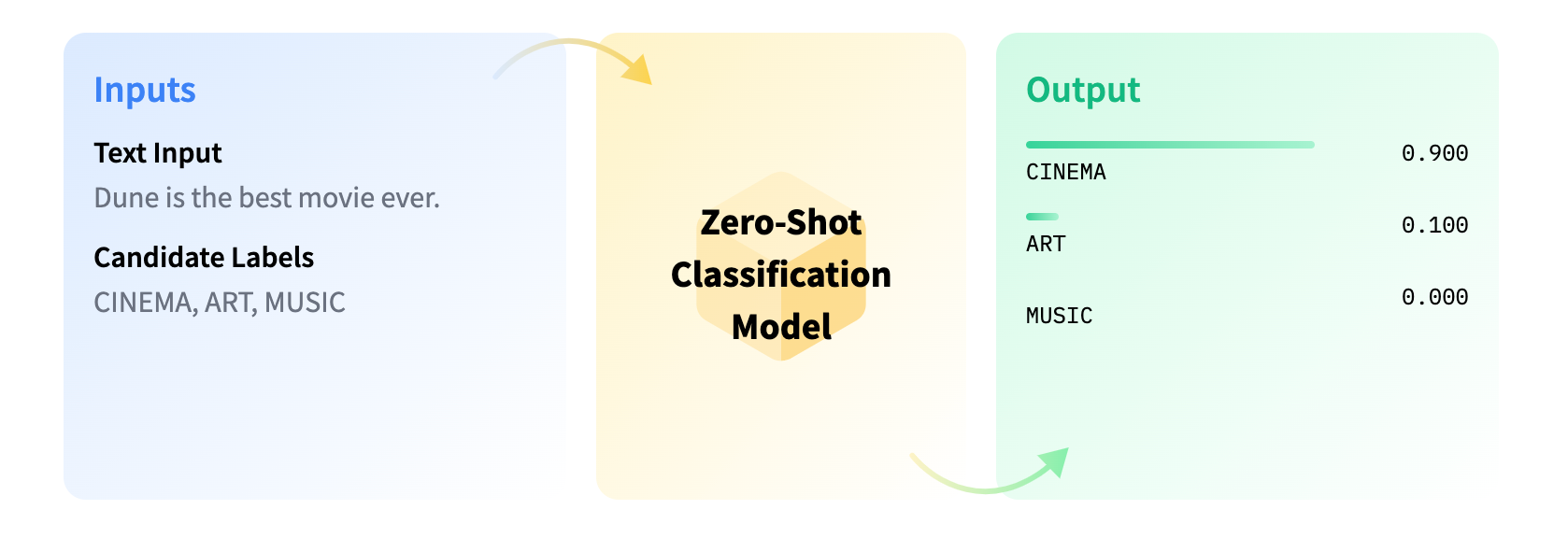
Zero-shot text classification is a task in natural language processing where a model is trained on a set of labeled examples but is then able to classify new examples from previously unseen classes. Image source: Hugging Face: Zero-Shot Classification
The first strategy considered involves the use of zero-shot text classification enabled by advanced open-source language models. The process itself is straightforward, with the most challenging aspect being the definition of candidate_labels.
These labels are essential as they determine the categories for tag classification. It is crucial to define labels that not only accurately represent fashion-related objects of interest but also to establish categories for items that are unrelated to fashion.
Identifying categories related to fashion, such as apparel, shoes, bags, and accessories, is fairly straightforward. However, defining categories for non-fashion items is more complicated due to the wide variety of potential non-fashion objects. While employing generic labels such as “others” or “non-fashion” might seem like a quick solution, this method has its shortcomings. For instance, the term “others” can have vastly different meanings in various contexts and is not particularly descriptive.
A more nuanced strategy would be to implement thresholds that only preserve predictions with substantial confidence levels. Another approach could be to use score entropy as a criterion, maintaining predictions with low entropy, which suggests a higher degree of certainty.
Develop Candidate Labels: An Iterative Process
The candidate_labels established for this specific use case are: ["people", "apparel", "shoes", "bag", "accessories", "furniture", "food", "background", "place", "photo", "transport", "other"].
An iterative process is employed to develop the candidate_labels, focusing primarily on capturing key fashion objects such as apparel, shoes, bags, and accessories. Detailed fashion subcategories are omitted, as the goal is to cluster fashion objects collectively, not by individual subcategories.
Additionally, it is observed that the original free-form tags are frequently human-centric, encompassing terms such as women, girl, boy, man, and so on. Consequently, the category "people" is introduced to cover these tags. This inclusion proves advantageous, as identifying "people" can also facilitate the detection of their outfits, which are relevant to fashion.
"Furniture" is also included as a category due to its potential relevance to style and fashion, opening the possibility for later clustering. A similar rationale applied to the inclusion of "food".
For the remaining labels, "background" and "other" are initially selected to encompass non-fashion-related objects. Yet, to address tags not effectively classified by "background" or "other", extra categories such as "place", "photo" and "transport" are introduced. Interestingly, tags associated with these three categories often get misclassified as "people", making their inclusion crucial to accurately differentiate them from the "people" category.
Results
The zero-shot classification procedure becomes quite straightforward once the taxonomy is established.
The classificationresults appear somewhat like this:
| tag | accessories | other | place | background | apparel | photo | transport | bag | people | food | shoes | furniture | group |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| swimwear under | 0.015388 | 0.236125 | 0.101356 | 0.061311 | 0.481701 | 0.033775 | 0.017324 | 0.024910 | 0.011028 | 0.007460 | 0.005789 | 0.003834 | apparel |
| bathroom sink sink | 0.023469 | 0.113758 | 0.736379 | 0.032409 | 0.006332 | 0.050788 | 0.008616 | 0.008879 | 0.006865 | 0.005167 | 0.003332 | 0.004006 | place |
| adjust wedding dress | 0.025955 | 0.126322 | 0.166667 | 0.024531 | 0.498195 | 0.090956 | 0.023469 | 0.013250 | 0.013402 | 0.007799 | 0.005129 | 0.004325 | apparel |
| bag briefcase | 0.124203 | 0.067845 | 0.059877 | 0.023308 | 0.003638 | 0.007318 | 0.089590 | 0.615467 | 0.003580 | 0.001835 | 0.001604 | 0.001736 | bag |
| porch stand | 0.024327 | 0.09596 | 0.561936 | 0.083579 | 0.003906 | 0.018671 | 0.002503 | 0.002670 | 0.006880 | 0.002461 | 0.001175 | 0.195896 | place |
Challenges of the Design of Taxonomy
The overall process is straightforward and efficient. However, it’s important to recognize that the design of the candidate_labels, including the specific wording used, can have an unpredictable impact on classification outcomes.
For instance, in zero-shot text classification experiments, tags like "girl" and "actor" are often misclassified as "other" instead of "people." Introducing new labels such as "child" and "profession" can improve accuracy for these specific tags, but similar issues persist with other tags.
Expanding the taxonomy might seem like a solution, but it’s an inefficient process. It involves reviewing classification results, adding new classes, and re-running the classification multiple times. Moreover, altering the taxonomy can also change the initial classification results for tags previously thought to be correctly classified.
Challenges of the Choice of Model
The success of zero-shot classification also depends heavily on the selected pre-trained language model. In this case, the bart-large-mnli model from Facebook was utilized. However, the field offers a variety of other potent models suitable for text classification.
Choosing a specific model significantly influences the classification results. This highlights not only the importance of careful model selection but also the inherently unpredictable nature of employing zero-shot classification for this particular use case.
Implementation Details
Input
| Name | Description |
|---|---|
ins_posts_object_tags_cleaned.csv | csv file containing objects with both raw and cleaned tags |
Process
| Code | Description |
|---|---|
codes/object_grouping_and_filtering/text_classification.ipynb | Zero-shot text classification |